Scientific rationality, human fuzziness, and trendy corporate logic
Here’s a blog post in preparation for the presentation I’ll be giving at the AI workshop organised by the Crihn (this is why it is in English) in partnership with the Conference Chatting in Academia? The impact of large language models and conversational agents on literary studies. It is also a response to a discussion I had on mastodon following my post on LLM creativity.
I’m going to continue my reflection on what I call the factory of subalterns.
The media craze for algorithms known (in my opinion wrongly) as ‘generative AI’ questions and perplexes me. The uses of these algorithms in the scientific field – specifically in the humanities – leave me even more dumbfounded.
So the question I’m asking myself is: what are we attaching symbolic value to, and why?
Why are we so excited by a chatbot that babbles in natural language, while a programme that calculates the exact time of the next solar eclipse leaves us completely indifferent?
Let’s start with a strange expression that has completely fallen into common usage: “generative AI”, to refer to recent inductive algorithms – and more specifically algorithms based on transformers. The mass media – and, unfortunately, much of the discourse that claims to be “scientific” – seems to suggest that “artificial intelligence” was born in 2017 with the famous article Attention is all you need, the text that launched the development of transformers. Or at any rate it seems to be asserting that artificial intelligence wasn’t capable of “generating” anything new before, and that now it is. I think it’s worth pointing out that this idea is completely false.
First of all, “artificial intelligence” has been around for at least 80 years, since the beginning of computer science. And probably even before that: Pascal, Leibniz, and before him Llul, and before that… even Pythagoras… all of them – and many others – worked on creating formal models that would make it possible to automate “intelligent behaviour” or “rationality” or “understanding”.
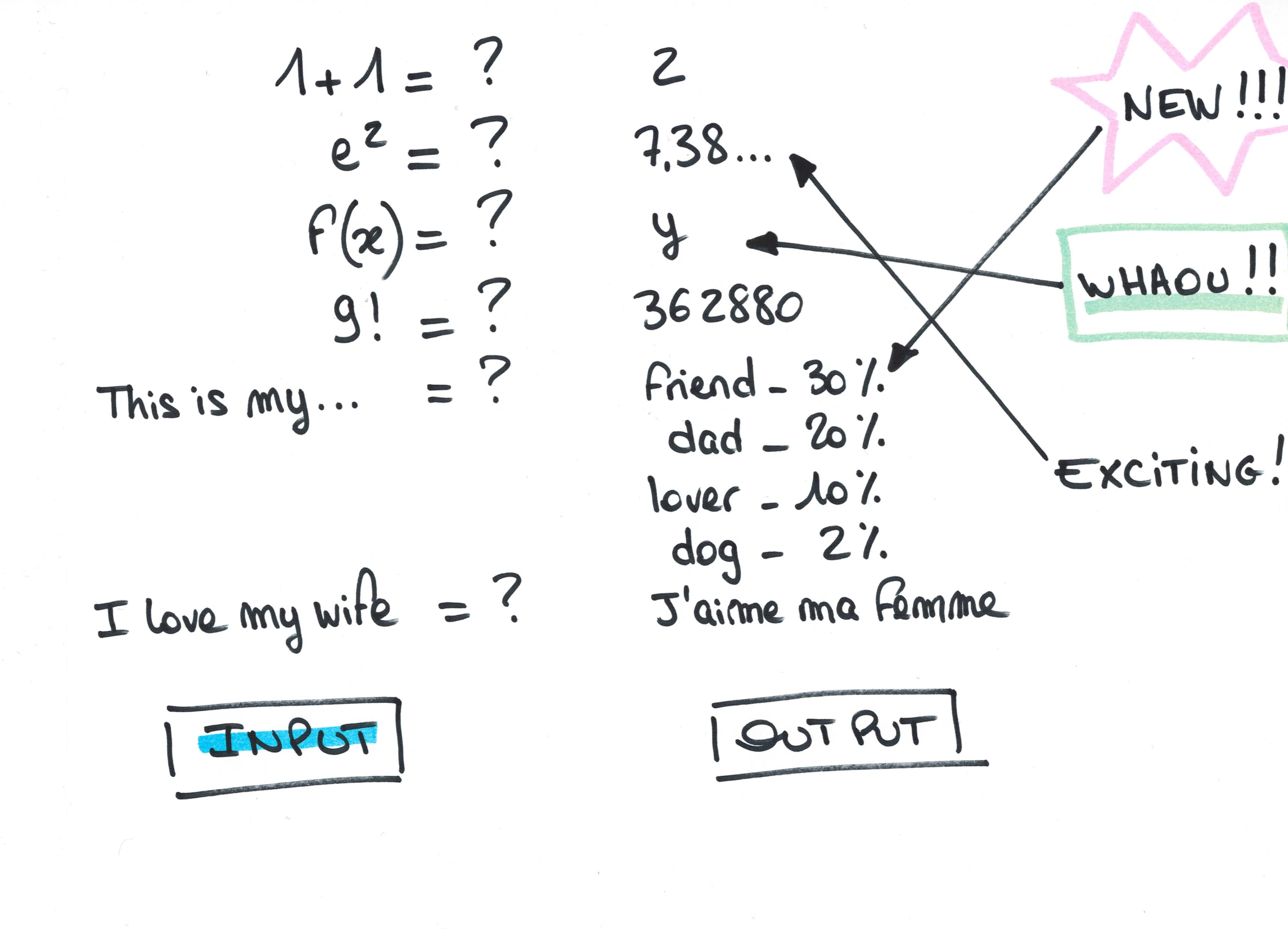
Secondly, let’s talk about “originality” or the ability to produce something “new”. Machines have always “produced” new things. If you give a machine the expression ‘1+1’, it generates something new by outputting a 2.
This is definitely the generation of something “new” – the output is not contained in the input. If you make the expression more complex: Let us say , the ability to “generate” something new is even more evident. Who can guess the output? (my calculator says 0.704931082, I guess it is an approximation)
This point is made very clear by Turing in his famous paper Computer machinery and intelligence, where he writes:
A variant of Lady Lovelace’s objection states that a machine can ‘never do anything really new’. This may be parried for a moment with the saw, ‘There is nothing new under the sun’. Who can be certain that ‘original work’ that he has done was not simply the growth of the seed planted in him by teaching, or the effect of following well-known general principles. A better variant of the objection says that a machine can never ‘take us by surprise’. This statement is a more direct challenge and can be met directly. Machines take me by surprise with great frequency. This is largely because I do not do sufficient calculation to decide what to expect them to do, or rather because, although I do a calculation, I do it in a hurried, slipshod fashion, taking risks. Perhaps I say to myself, ‘I suppose the voltage here ought to be the same as there: anyway let’s assume it is’. Naturally I am often wrong, and the result is a surprise for me for by the time the experiment is done these assumptions have been forgotten. These admissions lay me open to lectures on the subject of my vicious ways, but do not throw any doubt on my credibility when I testify to the surprises I experience.
This Turing quote makes me think that the point is not to understand whether a machine can generate something new, or whether a machine is less or more able than a human to do something – whatever that something may be. The point is to understand why we are less or more “excited” by what a machine can do. Turing seems to be quite excited by the fact that a machine can do complicated calculations… but normal people aren’t, they are more excited by chatGPT. Why?
One reason is certainly the fact that managing natural language is not an easy action to model. In other words, speaking a natural language is something that is quite easy for a human being, a child can do it, it doesn’t require rare skills, but when we try to give a precise account of how this skill works, it’s quite complicated to have an answer. And actually… we don’t have one. Speaking is not a scientific and rational activity of ours. It’s not a scientific skill. Adding 2+2 is. This means that we can speak without knowing anything about language, without having any scientific knowledge about it; but in order to be able to add 2+2, we must have a scientific knowledge of mathematics.
This is the distinction I make between “scientific rationality” and human fuzziness. We deal with many things, activities, behaviours… in our lives. Most of them are not well defined. In fact, we have no idea what we are doing, we just do it. We are very fuzzy about most of the things we do. Now
Is this the “nature” of human beings? Is that what defines us, what is most interesting about us? I don’t think so… Because actually we can also be rational, scientific. That is the part that interests me more, that is what I think is really intelligent about us – and Turing seems to think the same.
Now, if we have scientific knowledge about something, as Donald Knuth says, we can teach a computer to do it.
Science is knowledge which we understand so well that we can teach it to a computer; and if we don’t fully understand something, it is an art to deal with it. Since the notion of an algorithm or a computer program provides us with an extremely useful test for the depth of our knowledge about any given subject, the process of going from an art to a science means that we learn how to automate something. Knuth, Computer programming as an art
Let us come back to the interest of creating an algorithm that would be able to speak: this could be the fact that in order to create such an algorithm we would have to develop a huge amount of knowledge about natural language. In order to be able to model natural language we should have a scientific understanding of it.
But now it is necessary to make a very important distinction: the difference between the study of LLMs and the algorithms on which they are based, and the use of them. I’d like to show here that while the former may give us interesting scientific insights into what language is and how it works, the latter cannot be of any scientific use.
The problem that concerns me today is that I see more and more “use” of these algorithms and less and less critical analysis of them. And that is really scary. I am really worried because I feel that the future of the humanities as a form of science is being seriously compromised by the acritical, stupid use of these algorithms, a use based on a serious misunderstanding of what they are and how they work.
This trend is probably caused by what I call in my title trendy corporate logic. Here I will first analyse this logic and their aberrant consequences, and then conclude with a suggestion as to what may be of interest in the study of the LLMs.
It seems to me that corporate logic is definitely taking over scientific interest. The question to be asked is “What is science?” and what are its aims? Noam Chomsky said at a conference in 2018:
There is a notion of success which has developed in computational cognitive science in recent years which I think is novel in the history of science.See transcript here
Now, Chomsky’s remark - which should be commented on in detail, as Norvig has done here, but that’s not our purpose - seems to me very interesting because it underlines the fact that we are more and more used to thinking about science on the basis of its “results”, or more precisely, on the basis of its applied results.
For example, I have heard people say that they use chatGPT for tasks like HTR transcriptions or TEI markup – or bibliography structuring, as openIA itself suggests (Arthur Perret talks about this here) – and claim that it “works well”. The result is rapid and comparatively “good”.
The problem is that such an activity cannot be considered scientific, whatever the result. You can have any result you want, as impressive as you want, as “good” as you want, but if the methodology you have used is not “rational”, which means well described, reproducible, explainable and appropriate for what you want to do, your results will not be scientific. You may succeed in calculating a very complex formula by chance… that is not science. Similarly, if the result is “possibly correct” but the process is not well understood, the result is not scientific.
And all we can do with an LLM will not have a scientific methodology, for many reasons. Firstly, LLMs have stochastic behaviour, whereas science is deterministic: if you do an experiment twice, you should get the same results if your methodology is sound. Secondly, in order to use a “tool” in research, one should be fully aware of how it works - and we do not know much about how LLM-based applications work (we can know things about the models, but the implementation in applications is proprietary and completely opaque). Thirdly, a methodology should be built ad hoc for the purpose of a particular scientific work – and in the case of LLM-based applications, we tend to use the same application for every purpose.
Science is all about understanding the world. Results can be useful for understanding the world, but they are not the goal of science. But we live in a capitalist world where profit seems to be the only imperative. This is why we prefer to use chatGPT: we can save time, be more productive, get results, add lines to our CVs, produce more… This is what we value most. And in this capitalist mood, we actually prefer something shiny – like a nice advertisement – than something insightful – but very hard to sell – like a scientific knowledge.
So babbling is more valuable than being rational.
Chatting seems to be the most valuable skill we have: human intelligence is the art of babbling. This is more or less the idea that Turing proposed in his paper Computer machinery and intelligence. And I would like to say a word about it. Why does Turing define the ability to “think” as the ability to “play a social game” – the imitation game? Turing’s point is to say that “if thinking is the behaviour we have in our social interactions, then a machine can think”. If you read Turing’s paper carefully, you immediately realise that he is being deeply ironic throughout the text. He is actually playing around. The point is to say: yes, if small talk is what you value most, then certainly a machine can do that. He is not saying that a machine can be intelligent, he is saying that humans are so stupid! In the examples he gives, it is very clear: a machine should pretend not to be able to do a calculation quickly, because if it is too good, you will obviously know that it is not a human being.
So the obvious answer to the question of whether a machine can be as good as a human being is yes, because humans are really dumb.
Now let’s consider our second point: how studying, not using, LLMs can be of scientific interest. The fact is that human fuzziness is complicated to model. Precisely because some of our activities are not science, but, as Knuth says, just a form of know-how, of art, it is interesting from a scientific point of view to analyze them in order to gain more knowledge about them and to transform them into something more scientific.
Language is a very good example: as I said, we know how to speak, but we do not know why.
To gain some insight into language, it is interesting to analyze how LLms work and why they seem to be so good at manipulating natural language. As Juan-Louis Gastaldi – among others – has shown in many of his works (e.g. here and here), the whole development of LLMs is based on a structuralist view of language. The main idea is to consider language as a closed system and meaning as something that emerges from the relations that the “elements” of language have with each other.
(This first consideration is also very important to limit the possible use of LLMs: the models are trained on the basis of this structuralist hypothesis, and it is therefore impossible for them to implement any notion of “truth”, if we define truth as the correspondence between a linguistic expression and a fact. )
The fact that LLMs seem to be good at manipulating natural language thus seems to confirm – partially – the structuralist view. Knowledge of the internal relations within language as a closed system is sufficient to be able to speak.
There are many objections to this statement: for example, the fact that an LLM needs a huge amount of data to be able to produce sound sentences, whereas a child can do it by being exposed to a much smaller corpus.
But we can ignore these - correct - objections for now and focus on what we can understand about language based on the analysis of LLMs.
The point here is to try to understand precisely what these relationships are, not to have a vague sense of them. The algorithm allows us to have a formal understanding and thus, as Knuth suggests, to transform a vague knowledge into scientific knowledge. So how do LLMS model these relations? By closely studying how the relationships are formed and transformed into vectors, we can gain insight into how possible manipulation of NL works.
In order to do this, it is important to distinguish between the way an LLM is trained and the way it can be used. What is interesting for understanding language is more the former than the latter (for many reasons, the most important being the fact that applications are often very opaque). Most LLMs are trained on a corpus by giving a list of words (or better “tokens”, because tokens are not really words, but this is another story) as input and a distribution of probabilities on some other tokens for the latest token as output. For example:
:::: {.language-plaintext .highlighter-rouge} ::: highlight
Input: Eiffel Tower is in <mask>.
Output: Paris = 50%, France 40%, Europe 7%...
::: ::::
This can also be done by masking tokens within the sentence. For example:
:::: {.language-plaintext .highlighter-rouge} ::: highlight
Input: Eiffel <mask> is in Paris
output: tower 80%, building 10%...
::: ::::
These input/output pairs (taken from the corpus) are used to inductively find a vector for each token that can describe its semantic position in the n-dimension space of the language (where n is the number of “parameters” used by the model). The model will consist of the set of all vectors describing the language. The process of calculating the vector of each token in the training of an LLM can be divided into the following steps:
- Identifying tokens (this is normally made with byte pair encoding)
- Encoding: transforming each token in a one-hot encoding vector
- Embedding: transforming the hot encoding in some vector describing the semantic position of the token
- Attention: adding some vectors in order to represent some relationships between token in each sentence (this is the new approach introduced with transformers)
- Feed foreword (a multilayer perceptron to learn the final weights and get the final hidden layer
- Normalization and softmax (some normalisation and a softmax in order to get the probability distribution)
A deep analysis of each of these steps allows to understand more precisely what kind of relationships are represented in the LLM. This work of analysis seems to me the most interesting thing to do today. In particular, the relations between tokens in a context are represented thanks to the attention mechanism. Attention consists in creating three other vectors, one (the query) that tries to point to tokens that are related to the token we are analyzing, a second (the key) that represents the target token, and a third (the value) that represents the value of the target token. If the query and the key are close, it means that we can add the value of the target token to the token we are working on to change (transform) its meaning, moving it in the direction of the target token. Obviously, these three vectors are learned by the model thanks to a neural network.
Formally:
What exactly does that mean? This is the question we must ask. Because this is how the distribution hypothesis is “formally” interpreted by LLMs. In other words, a deep understanding of how relationships between tokens are computed should allow us to produce a “scientific” interpretation of how language is represented by LLMs. And here, the fact that it looks like LLMs are able to manipulate natural language is a hint to us that their representation may be an interesting way to understand language.
And I think that’s what science is all about. Not chatting with a chatbot, but trying to explain the phenomenon of chatting. Trying to turn the fuzzy capacity of chatting into something that can be well described and understood. Trying to understand the world.
